Just listened to a nice piece on Reply All about Yik Yak, which is app where users can post messages anonymously and see the messages of those nearby (10 miles). The podcast mentioned how it was useful in showing written evidence of racism that previously was hard to prove. It got me thinking that if there was a way to get the feeds from different universities then one could analyze these using Natural Language Processing routines to get metrics for different schools. What percentage of anonymous posts at your school are about race, violence, sex, etc.? Could be something prospective students might want to know.
Friday, January 30, 2015
Wednesday, January 28, 2015
Prediction markets for human capital investment
While there has been a growing literature on prediction markets, most of the markets have been confined to politics and macro-economics. These are great to have, but I would like to see markets that could help with more decisions that typical people make, such as when, and in what field to get training. The information that people have is usually about the current economy (this industry currently has a tight labor market) or employment projections by the government. What could be better would be a set of markets about future industry-specific indicators such as vacancy rates. If they were started at least 2-3 years before maturity then it could be used by people in college to help pick a major or by workers deciding whether to get training in a new field. The market might have to be "seeded" by the government, but it could be worth it.
Tuesday, January 20, 2015
Getting latexmk working within LyX
If you would like to add latexmk as an export option in Lyx, here are the two basic steps to do in Tools -> Options.
1) In File Handling -> File Format, hit "New" and then put in these options, then "Apply".

2) Then in File Handling -> Converter, click on any existing converter, change the options to the below, and then click "Add", then "Save".
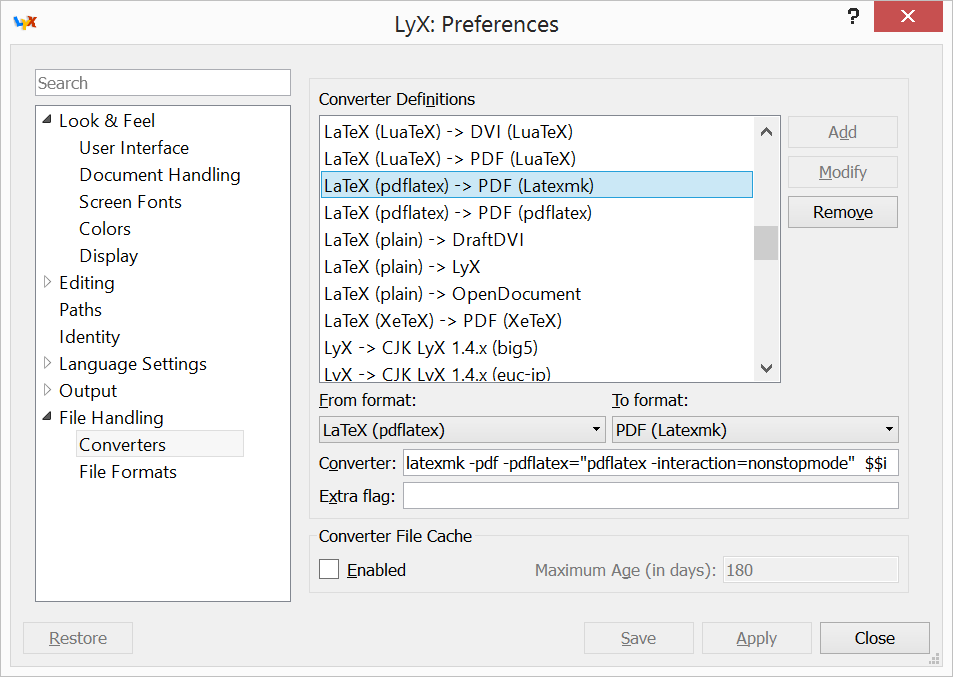
If you are on Windows, then you might have problems with Perl versions (Lyx has one, MiKTeK another). Initially, I was getting that perl couldn't find File::Glob in @INC when latexmk was run. Turns out that Lyx was running it's own version of perl 5.18.2 and had @INC set to just the Lyx/lib (which oddly did have File/Glob.pm). I installed Strawberry Perl same version (needed that!) then set the PERL5LIB to the Strawberry perl folder. Then it works fine.
This was on LyX 2.1.2, updated MiKTeX, and Windows 8.
Running Stata 12 on Ubuntu 14.04 (Trusty Tahr)
After upgrading my linux machine I realized that I could no longer run my copy of Stata 12 GUI. It game the error:
./xstata-se: error while loading shared libraries: libgtksourceview-1.0.so.0: cannot open shared object file: No such file or directoryThese older versions of libraries aren't in the normal Ubuntu repositories anymore, so this is a simple work around to get Stata working again. (I'm on a 64 bit machine so change amd64 to the appropriate)
- Install libgtksourceview2-2.0
- sudo ln -s /usr/lib/libgtksourceview-2.0.so.0 /usr/lib/libgtksourceview-1.0.so.0
- Download libgnomecups1.0-1 0.2.3-4 from here. Install it with dpkg.
- Download libgnomeprint2.2-data_2.18.8-3ubuntu1_all.deb and libgnomeprint2.2-0_2.18.8-3ubuntu1_amd64.deb from here. Install them at the same time with dpkg.
Tuesday, November 25, 2014
Graphs with log-scales in the positive and negative domains
Often to show data that is highly dispersed one will compress the data by graphing its log. One down-side of this is that it only works if the data is all-positive or all-negative (if you use \(-ln(-x)\)). If your data contains zero and/or points in both domains then the you have to do something else. Here is a simple extension that uses a linear function around zero to smoothly connect a log function and it's opposite. $$x= \begin{cases} \ln(x) & \text{if }x>e\\ x/e & \text{if }-e\leq x\leq e\\ -\ln(-x) & \text{if }x<-e \end{cases}$$ The function is log-linear-log ("trilog").
 You can get a simple Stata utility -trilog- from here to make this transformation and create axis labels.
You can get a simple Stata utility -trilog- from here to make this transformation and create axis labels.
Another intuitive extension would be to shift the log and its opposite closer to zero, such as $$x= \begin{cases} \ln(x+1) & \text{if }x\geq0\\ -\ln(-x+1) & \text{if }x<0 \end{cases}$$ The downside of this is that no longer are equal proportional changes reflected as equal distance changes.
Another intuitive extension would be to shift the log and its opposite closer to zero, such as $$x= \begin{cases} \ln(x+1) & \text{if }x\geq0\\ -\ln(-x+1) & \text{if }x<0 \end{cases}$$ The downside of this is that no longer are equal proportional changes reflected as equal distance changes.
Wednesday, November 19, 2014
Using make with Stata
Having a makefile helps automate a lot of tasks with a project.
- Generating different formats of logs, tex tables, and gphs (including making versions of the figs that have no titles). And removing orphan files if the primary ones are removed.
- Normalizing logs, gphs, and dtas prior to committing.
- Generating PDFs of Lyx files.
- Updating the project mlib when mata files change.
- Installing updated versions of packages that have to be installed.
- Running Stata in batch mode, knowing the dependencies between code files (and setting up a gateway file so that on Windows modules can run shell commands).
- Deals with SVN commands.
Here is stub version. It uses statab.sh, cli_build_proj_mlib.do, gph2fmt.ado, cli_gph_eps.do, cli-install-module.do, cli_smcl_log.do (plus the normalizing ones).
Edit 2015-01-28: I've posted a project template with updated versions of these (and better makefiles as my skill improves) at GitHub.
Edit 2015-01-28: I've posted a project template with updated versions of these (and better makefiles as my skill improves) at GitHub.
Version control for research projects
While I had used version control on earlier projects, I didn't start using version control for collaborative research projects until reading Code and Data for the Social Sciences: A Practitioner’s Guide by Matthew Gentzkow and Jesse M. Shapiro. If you haven't read it, it's a good read (I agree with the general guidelines and most of the specifics).
The first decision is which files to version. I version the dta, gph, tex, and log files. I chose not to version easily generated files such as different formats of outputted figures and tables and instead generate them automatically using my Makefile. I normalize the dta, gph, and log files before committing them so that changes are noted only if real content has changed.
Some miscellaneous tools: rm-non-svn.sh, svn_batch_rename.sh.
The first decision is which files to version. I version the dta, gph, tex, and log files. I chose not to version easily generated files such as different formats of outputted figures and tables and instead generate them automatically using my Makefile. I normalize the dta, gph, and log files before committing them so that changes are noted only if real content has changed.
Some miscellaneous tools: rm-non-svn.sh, svn_batch_rename.sh.
Stata wishlist
Here's what I wish Stata would add:
- Primary output files (dtas and gphs) should be able to be reproduced byte-for-byte. Primarily this requires being able to zero-out the timestamps and zero-out any junk padding.
- Make PDF and PNG exporting of figures available on console Unix.
- Shell commands should work in Windows batch-mode.
- All built-in commands should return values through the return classes (e.g. r()) so that they can be used programmatically
- Also, allow the Windows do-editor to automatically word wrap (this is a main reason why people I know use other editors).
- The program should set a positive return code on error. When running Stata in batch-mode the program always exits with 0 (success) even if the program had an error.
Hopefully, some of these will be available for version 1415.
Monday, October 13, 2014
Module to sort Stata matrix by column
I noticed recently that the module to sort Stata matrices by a column (matsort) incorrectly handles row names with spaces. This error is partly due to the limited Stata functions available for handling matrices prior to version 9 (when Mata was introduced). I've quickly made a bug-free replacement -matrixsort- that you can download from my Github repository.
Sunday, October 12, 2014
Bookmarklets
Here are two bookmarklets that I created recently:
- 0){N=T[0];N.outerHTML = N.innerHTML;T=d.getElementsByTagName(t);}}}catch(E){r=0}return r}R(self);var i,x;for(i=0;x=frames[i];++i)R(x)})()">CleanupSingleDoc which I use (with Printliminator) to save a simple version of a web page (remove text links, iframes, etc.) in order to save the content as an ePub (using Calibre).
- Connect via ResearchPort which will append the University of Maryland suffix proxy for authentication
Friday, October 10, 2014
Managing sets of files produced by different configurations
With statistical estimation you often run the same programs multiple times with slightly different options. If these program produces file outputs you can have some trouble managing them all. Here are some tools I use. I have a global suffix ${extra_f_suff}
$ cat file_list | xargs rm # delete
#manage them via svn (similar options for git):
$ cat file_list | svn add --targets -
$ cat file_list | svn remove --keep-local --targets -
$ cat file_list | svn commit -m "" --targets -
Tracking sets
The first task is tracking the files produced. In general you want to have files names that include the option. Here, I employ two strategies depending on the work.- For real runs, I usually want to collect the names of all files produced so that they can be checked and then stored/deleted/etc. Therefore I have wrapper functions saving dtas, logs, graphs, tables, and text snippets that append the name of the file they are writting to a separate text file.
- A standard option that I always include is a "testing" switch. This is useful for when I want to just test if a small change causes an error. It does the bare minimum for a program (limits the number of observations, reduced the number repetitions, etc.). It also sets a global extra_file_suffix="_testing" which is appended to all file names at the point of file writing (easier than passing a testing option through several layers of programs).
Manipulating sets
If you can build a list of files (either because they were saved or you do find | grep *.blah) then here are some handy tools for dealing with them.$ cat file_list | xargs rm # delete
#manage them via svn (similar options for git):
$ cat file_list | svn add --targets -
$ cat file_list | svn remove --keep-local --targets -
$ cat file_list | svn commit -m "" --targets -
Noting the primary key in Stata files
Most tables in databases have a primary key defined and this can be a help with Stata files too. If you have a primary key defined by a single variable then you can use xtset (or tsset if it's a time variable). If you have a composite key and one of them is a time variable you can use xtset/tsset. Otherwise, you should have a consistent way of listing it. One way is to store it as a dta characteristic, such as:
. char _dta[key] keyvar(s)
See also isid.
. char _dta[key] keyvar(s)
See also isid.
Thursday, August 28, 2014
Parallel processing in Stata: Example code
Here are some files from a presentation I did about running parallel operations in Stata (beyond what Stata-MP does). They include a simple presentation covering the basic idea and example code for doing parallel bootstrap estimation. They use the parallel Stata module (I prefer dev version).
Wednesday, August 27, 2014
Easy LyX Beamer products
When making presentations in LyX with the Beamer template, one often wants to make three PDFs every time: slides, handouts, and handouts+notes. Here are some scripts to do this. You will need Cygwin installed if you are on Windows.
Command-line version:
In Windows I've added this functionality to the right-click menu for LyX files. It requires the slightly modified script below. To edit the right-click menu I use the FileMenu Tools utility. In a new entry, set the program as a shell (I've tested git -- "C:\Program Files (x86)\Git\bin\sh.exe" and cygwin -- "C:\cygwin64\bin\mintty.exe"). For arguments put "absolute/path/to/beamer_outputs.sh %FILENAME1%".
Command-line version:
In Windows I've added this functionality to the right-click menu for LyX files. It requires the slightly modified script below. To edit the right-click menu I use the FileMenu Tools utility. In a new entry, set the program as a shell (I've tested git -- "C:\Program Files (x86)\Git\bin\sh.exe" and cygwin -- "C:\cygwin64\bin\mintty.exe"). For arguments put "absolute/path/to/beamer_outputs.sh %FILENAME1%".
Monday, August 25, 2014
Storing Stata project dependencies
Newer versions of an environment can break existing code so it is often helpful to maintain access to the specific versions you use. For the Stata environment this is particularly important. The SSC archive doesn't store previous versions of modules so you should store them in your project folder. To ensure that a project is using only the locally-stored Stata programs, I set the shell environment variable S_ADO to "\"<project_base>/code/ado/\";BASE".
The process is a bit more work if a module has machine-specific files (e.g. compiled plugins) and you want to allow your project to run on different platforms. If you're working across platforms you should have your code stored in some kind of version control repository (e.g. subversion or git). For modules with machine-specific file you can't store the installed files in the repo since they differ constantly between machines. Instead you store the installation files in the repo and then you do a local install on each machine. To store the installation files locally, find the URL of pkg files (e.g. http://fmwww.bc.edu/repec/bocode/s/synth.pkg) and use store-mod-install-files.sh. To install locally, do the following
A more general solution will reinstall the files when the the installation files are updated. For this we use make and generate the makefile. The file dependencies are stored in a the pkg files so you can use gen-makefile.sh (and statab.sh and cli-install-module.do) to scan for such files, extract the dependencies, and generate the makefile.You will then be able to type:
$ make all_modules
to update/install all the modules.
For the paranoid: The Stata program itself is closed-source, so specific versions may be unavailable in the future. Stata states that you can use the version command to enable dated-interpretation in newer versions. If you are not satisfied by that, store installation files yourself (preferably for an open-source system like Linux).
The process is a bit more work if a module has machine-specific files (e.g. compiled plugins) and you want to allow your project to run on different platforms. If you're working across platforms you should have your code stored in some kind of version control repository (e.g. subversion or git). For modules with machine-specific file you can't store the installed files in the repo since they differ constantly between machines. Instead you store the installation files in the repo and then you do a local install on each machine. To store the installation files locally, find the URL of pkg files (e.g. http://fmwww.bc.edu/repec/bocode/s/synth.pkg) and use store-mod-install-files.sh. To install locally, do the following
A more general solution will reinstall the files when the the installation files are updated. For this we use make and generate the makefile. The file dependencies are stored in a the pkg files so you can use gen-makefile.sh (and statab.sh and cli-install-module.do) to scan for such files, extract the dependencies, and generate the makefile.You will then be able to type:
$ make all_modules
to update/install all the modules.
For the paranoid: The Stata program itself is closed-source, so specific versions may be unavailable in the future. Stata states that you can use the version command to enable dated-interpretation in newer versions. If you are not satisfied by that, store installation files yourself (preferably for an open-source system like Linux).
Thursday, July 31, 2014
Posting abandoned research ideas
Researchers often hold onto sub-par research projects for their option value. An idea might not seem worthwhile now, but maybe in the future (it might become feasible with better data or theoretical breakthrough, or might become more interesting if combined with another insight). But periodically, this option value drops. After a professor gets tenure they're probably much less likely to care about these long shots. Sometimes these ideas are lobbed at students, but they are often not picked up. I think that at these points where the option values drop, professors should post some of their least-likely-to-be-worked-on ideas somewhere. It could be their own blog, or a maybe an aggregator that specializes in abandoned research ideas.
Incentives and supply curves
I recently had thoughts about when exchanges between individuals are not exploitative. (I'm going to leave aside the issue of coercion though that is obviously related). Examples of "problematic" exchanges would be price hikes after events (like a storm) and blackmail. I think these are roughly in order of decreasing popularity. I'm going to steer clear of "repugnant markets" like organ sale.
The simplest thing to think of what happens in an exchange is that there is some surplus (as defined by their disagreement point or BATNA) from the transaction that should be shared evenly between the parties. This is the result from Nash bargaining. This setup, though, discounts the effects on possible future transactions. This is why many economists favor few price restrictions after calamities. If you don't allow people to profit, there won't be any supply response and the next time it happens (or later in the current after-math) the supply won't be improved. So in each case we are weighing the desire for equality with the desire to improve the world in the future. For price gouging we are then weighing a negative (short-term inequality) and a positive (improved future supply). Reasonable people could give different weights to these concerns and come to different conclusions (some events may be so particular that we don't think suppliers profiting now would cause any future benefit). Blackmailing is interesting because it is appears to be a negative in the short-term and long-term. The long-term is negative because if blackmailing was morally permissible it would incentivize people to violate the privacy of others.
Readings:
The simplest thing to think of what happens in an exchange is that there is some surplus (as defined by their disagreement point or BATNA) from the transaction that should be shared evenly between the parties. This is the result from Nash bargaining. This setup, though, discounts the effects on possible future transactions. This is why many economists favor few price restrictions after calamities. If you don't allow people to profit, there won't be any supply response and the next time it happens (or later in the current after-math) the supply won't be improved. So in each case we are weighing the desire for equality with the desire to improve the world in the future. For price gouging we are then weighing a negative (short-term inequality) and a positive (improved future supply). Reasonable people could give different weights to these concerns and come to different conclusions (some events may be so particular that we don't think suppliers profiting now would cause any future benefit). Blackmailing is interesting because it is appears to be a negative in the short-term and long-term. The long-term is negative because if blackmailing was morally permissible it would incentivize people to violate the privacy of others.
Readings:
- Strings Attached: Untangling the Ethics of Incentives by Ruth W. Grant
- Questions for Free-Market Moralists by Amia Srinivasan (nytimes.com)
- Organ Sale - Stanford Encyclopedia of Philosophy
Thursday, June 19, 2014
Determining demand for unfinished products
Once a product has moved from the idea stage to the prototype stage, Kickstarter and similar sites are great ways to determine demand. But what about products that are still at the idea stage (but which are obviously feasible)?
The domain I was thinking about recently was audiobooks. I bet there are lots of potential long-tail audiobooks (especially older books) that aren't getting made because of uncertainty about demand. The existing systems to determine demand using the internet (that I'm aware of) likely don't allow many audiobooks to be published.
The domain I was thinking about recently was audiobooks. I bet there are lots of potential long-tail audiobooks (especially older books) that aren't getting made because of uncertainty about demand. The existing systems to determine demand using the internet (that I'm aware of) likely don't allow many audiobooks to be published.
- When an author tries to determine demand they will sometimes use a crowdfunding site (e.g. indiegogo which is very permissible in the type of project funded) to gauge demand. But this is very rare and I think authors of older books are very unlikely to do this.
- Amazon.com allows people to note their interest in an audiobook version on the book page. But amazon doesn't know how serious you are since it's practically costless to click that link. They also only use the data for make audiobooks through Audible.com which has a high production cost (potentially voice actors on ACX might do it for less).
What would be great was a site where people could monetarily show their interest (similar to indiegogo) on any potential audiobook and the site would track progress toward the goal. It would be more like bounty programs since the end-goal isn't specified and the producer hasn't been determined yet. Then entreprenuers could contact authors about audio rights (or authors could do it themselves). The site could even have free copyright as the end-goal like unglue.it for audiobooks. If that were the case, voice actors from LibriVox might record the audio for free and the payment would just be to secure the audio rights.
Monday, March 17, 2014
Stata's serset file format
Sersets are minimal versions of datasets in Stata. They are commonly embedded in .gph graphics files to store the data so that graphs can be reproduced by Stata. Sersets are sometimes also written directly to files. The file format is undocumented by Stata but very similar to Stata dta formats like v115 and previous ones. If you need to access the data in a serset file or .gph then here is the basic format. The below assumes that you are generally familiar with the dta v115 standard. Let nvar be the number of variables and nobs the number of observations. The length of each block is in brackets.
- [16] "sersetreadwrite" (null terminated).
- [1] either "0x2" for versions 11-13 (gph format 3) or "0x3" for version 14 (gph format 4).
- [1] I think this is a byte-order field, so 0x2 for lohi (standard Windows/Linux machines), otherwise 0x1.
- [4] Number of variables
- [4] Number of observations
- [nvar] The typlist. A byte characterizing the type of each variable.
- [nvar x 54] The varlist. Null-terminated strings of the variable names. For versions >=14 this is 150.
- [nvar x 49] The fmtlist. Null-terminated strings of the variable formats. For versions >=14 this is 57.
- [nvar x 8] The maximums. A double for each variable representing that variable's non-missing maximum. If the variable is a string then the double's missing value is used.
- [nvar x 8] The minimums. Same as above except for the minimums.
- [nobs x sum(sizeof each variable type)] Data: All data from an observation are contiguous.
Edit 2016-01-31: Figured out more about the bytes immediately after "sersetreadwrite" and about how version 14 is different.
Thursday, February 27, 2014
Subscribe to:
Posts (Atom)